硅光的概念早在20世纪90年代初便已被提出,但相较于集成电路的成熟发展和规模化应用,其在诞生之后的30多年里发展一直相对缓慢,产业生态系统尚不成熟。究其核心原因,在于尚没有巨大的应用场景驱动。随着云计算、大数据、人工智能的快速发展,社会对于信息获取与处理效率的需求持续攀升,但摩尔定律失效在即,硅光技术正凭借其在高通量、高能效比、超低延迟、低成本等方面的突出优势,成为确定性的技术发展趋势。
光通信领域——硅光芯片的主要应用场景。目前,产业内已基本建立了面向数据中心、光纤传输、5g承载网、光接入等市场的系列硅光通信产品pg电子直营网的解决方案,其中数据中心光通信是硅光的最大市场,微软的内部数据中心互连有超过40%是基于硅光芯片实现。数据中心场景下,云提供商(诸如facebook、apple、腾讯等)正转向大规模数据中心,capex支出持续提升以支持客户的高带宽需求,通信速率正由100、200g向400g、800g、1.6t、3.2t迭代,而且迭代周期持续缩短。在此背景下,传统的可插拔光模块在性价比及功耗方面已然“捉襟见肘”,而高集成高速硅光芯片由于在潜在降价空间与功耗方面有明显优势,则成为更优越的选项。市场的选择是最好的证明,目前100g硅光模块已局部商业成功,虽然400g、800g硅光模块渗透率不会有显著增长,但业内的共识是通信速率至1.6t阶段硅光模块应用将明显起量。
近年来,硅光已成为数据中心的关键组成部分之一。它利用光子的能量快速高效地远距离连接交换机、服务器和其他设备。随着带宽需求的不断增长,硅光必将变得更加重要。
硅光开始承担数据中心和ai超级计算机核心的cpu、gpu和其他xpu(其中“x”代表最适合特定工作负载需求的任何计算机架构)之间的芯片到芯片连接只是时间问题。
将光学和电子器件如此紧密地集成在一起是一个巨大的挑战。但半导体行业正在奋力应对这一挑战。新一代采用同封装光学器件的交换机芯片的兴起就是明证。
有一条途径,可以随着时间的推移将硅光子的功率效率(皮焦耳/比特)、带宽密度(tb/s/毫米)和成本(gb/s/美元)提高一个数量级。这将为一种更先进的共封装光学形式打开大门,这种光学形式被称为“晶圆级光学互连”,可以在印刷电路板 (pcb) 上或封装内的芯片之间以光速传输数据。
还有哪些领域看到高带宽光互连网络的出现?
最近,大型生成式ai模型的出现,凸显了在使用高性能ai/ml集群训练此类模型时网络带宽的重要性。可插拔光互连已经开始取代此类计算机集群中的铜(cu)互连,从而缓解了多xpu服务器之间相距几米到几十米的瓶颈。
但随着这些集群扩展到数千个xpu,光互连将逐渐进入电路板和封装,以满足芯片间高互连带宽要求。这一演变对带宽密度、成本、功率和可靠性等指标施加了更大的压力。需要带宽密度超过1tb/s/mm、功耗低于5 pj/bit、链路延迟低于100ns且可靠性高的光模块——所有这些成本为每 gb/s 10美分或更低。
与标准数据中心网络不同,ai/ml集群的功率和延迟预算非常紧张,几乎没有或根本没有空间进行数字信号处理。这意味着光通道需要非常“干净”,并且具有极低的误码率 (ber)。
在人工智能和机器学习的背景下,如何尝试利用硅光子学解决这些问题?
对于这些系统,扩展这些系统中的带宽的更合适方法是使用更多数量的并行光通道,每个通道以16至64gb/s范围内的数据速率无错误运行,使用针对效率而非带宽进行优化的光学和电气组件。反
过来,具有8、16或更多波长的波分复用 (wdm)有助于控制物理光通道的总数。
为了将光学i/o模块与xpu或高带宽内存 (hbm) 连接起来,晶圆级共封装光学器件正在兴起(见图)。利用节能的宽i/o电气接口实现“最后一英里”铜互连。最后,成本和光链路预算越来越成为将光源集成到sipho芯片上的驱动因素。
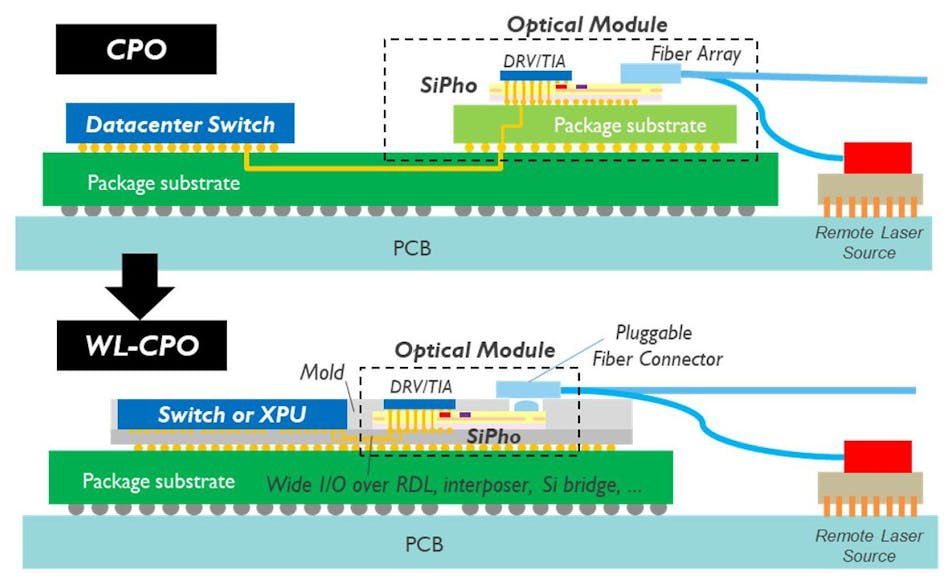
对于云数据中心和ai/ml集群而言,网络带宽已成为决定系统级性能的越来越重要的指标。网络瓶颈正在产生严重的紧迫感,从而促使业界大力推动硅光的采用。